truss push and any training workloads. A deployment scaled to zero replicas incurs no charges, but model load on a fresh replica is metered. See Billing and usage for the full lifecycle breakdown, and Cold starts for techniques to minimize startup time.
Reference
Reference
Baseten provides default settings that work for most workloads.
Tune your autoscaling settings based on your model and traffic.
- UI
- cURL
- Python
To configure autoscaling:
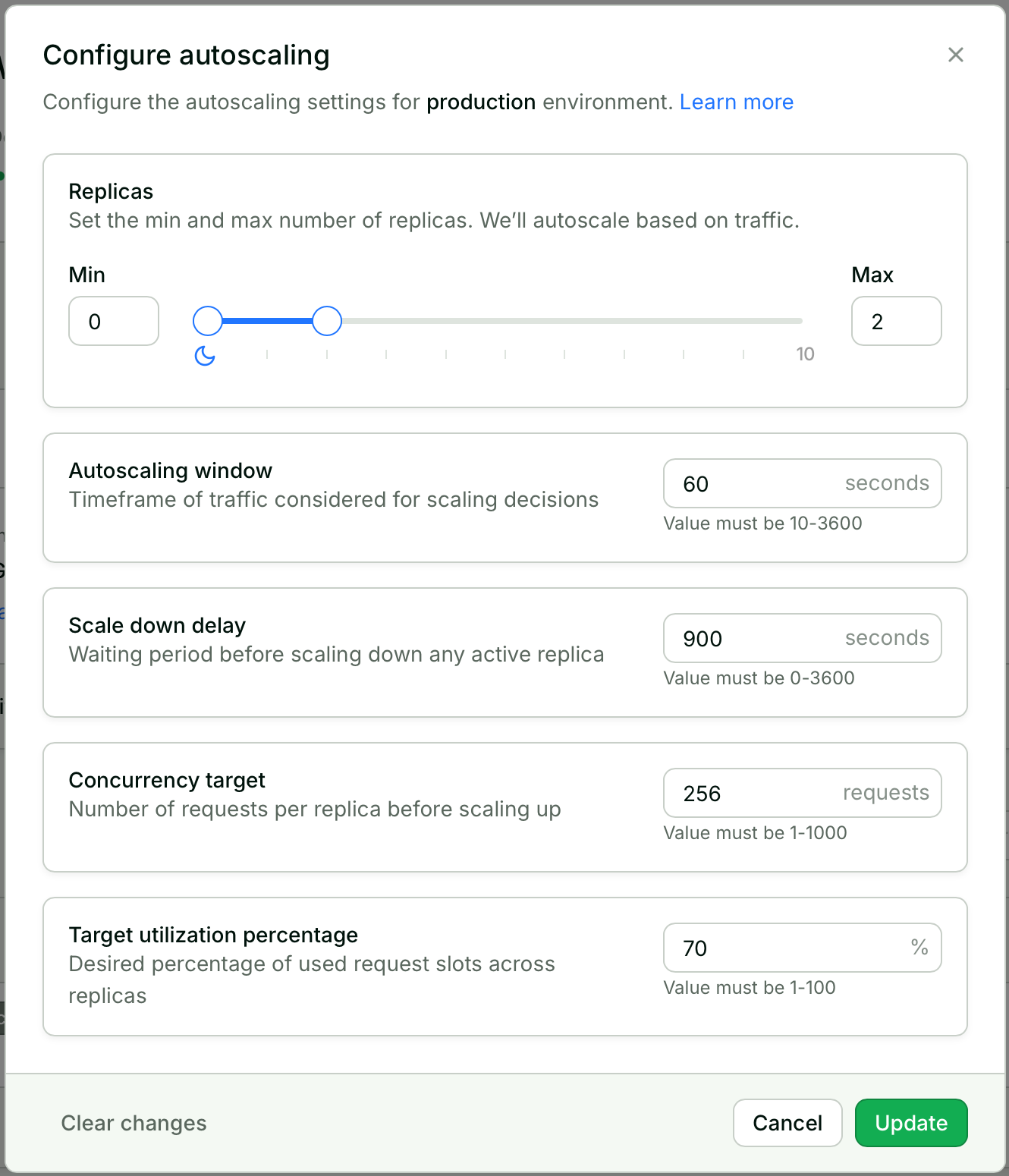
- Sign in to your workspace at app.baseten.co and choose Dedicated Inference in the sidebar, then select your model.
- Select your deployment.
- Under Replicas for your production environment, choose Configure.
- Configure the autoscaling settings.
- Choose Update.
Show the configure-autoscaling panel
Show the configure-autoscaling panel
How autoscaling works
The autoscaler matches replica count to demand by continuously sampling in-flight requests into a sliding window that spansautoscaling_window (60 seconds by default). It averages the load over that window, divides by each replica’s effective capacity (concurrency_target × target_utilization_percentage), and rounds up to set the desired replica count. Scaling up happens at the next decision, but scaling down is deliberately patient: load has to stay below the threshold for an entire scale_down_delay before the autoscaler removes replicas, and each step removes at most max_scale_down_rate of the running replicas (half by default) rather than dropping them all at once. That asymmetry is what keeps the deployment from oscillating when traffic dips and recovers.
The simulator below runs that exact loop on live traffic: every scale-up fires at the moment the windowed average crosses the scale threshold. Start from a scenario to stage a cold start or oscillation, or stay in the sandbox and shape the traffic yourself. Every parameter is live, and the meters track what your settings cost in idle capacity and queued requests.
To put numbers on it, consider a deployment with concurrency_target set to 10 and target_utilization_percentage at 70%. Each replica’s effective capacity is 7 concurrent requests (10 × 0.70). If the windowed average rises from 5 to 25 in-flight requests, the autoscaler computes ⌈25 / 7⌉ = 4 desired replicas at the next decision and starts provisioning the difference. Scale-up continues until the deployment reaches max_replica; beyond that ceiling, additional load queues until capacity frees up.
Scale-down is slower by design. When the windowed average drops below the threshold, the autoscaler waits a full scale_down_delay (900 seconds by default), removes the excess at a pace capped by max_scale_down_rate (50% of running replicas by default), and resets the timer. At the default rate, a deployment with eight excess replicas drains to four, then two, then one, with a full delay between steps. If traffic recovers inside the delay, no scale event fires and the replicas stay warm. Scale-down stops at min_replica; production deployments typically hold it at two or more so a healthy replica is always available.
Replicas
Each replica is an independent instance of your model, running on its own hardware and capable of serving requests in parallel with other replicas. The autoscaler controls how many replicas are active at any given time, but you set the boundaries.integer
default:"0"
The floor for your deployment’s capacity. The autoscaler won’t scale below this number.Range: ≥ 0The default of 0 enables scale-to-zero: when no requests arrive for long enough, all replicas shut down and your deployment incurs no charges. The tradeoff is that the next request triggers a cold start, which can take minutes for large models. During that wake-up period, billing is per minute even though the replica isn’t yet serving responses.
For production deployments, set
min_replica to at least 2. This eliminates cold starts and provides redundancy if one replica fails.integer
default:"1"
The ceiling for your deployment’s capacity. The autoscaler won’t scale above this number.Range: ≥ 1This setting protects against runaway scaling and unexpected costs. If traffic exceeds what your maximum replicas can handle, requests queue rather than triggering new replicas. See Request lifecycle for details on queuing and load shedding behavior. The default of 1 effectively disables autoscaling: you get exactly one replica regardless of load.Estimate max replicas:
Scaling triggers
The autoscaler decides when a replica is “full” by comparing in-flight requests against a per-replica threshold.concurrency_target caps how many simultaneous requests each replica accepts, and target_utilization_percentage cuts the threshold lower so the autoscaler can trigger a scale-up before any replica is completely saturated, leaving room for new replicas to come online without queueing requests in the meantime. Scale-up fires when:
The following diagram shows a replica with concurrency_target of 8 and target_utilization of 50%, so the per-replica threshold sits at 4. The first four requests fill capacity within headroom; the fifth crosses the threshold, and the autoscaler provisions a second replica to absorb the overflow before the remaining slots saturate.
integer
default:"1"
How many requests each replica can handle simultaneously. This directly determines replica count for a given load.Range: ≥ 1Given the current load, the autoscaler calculates desired replicas:In-flight requests are requests sent to your model that haven’t returned a response (for streaming, until the stream completes). Async inference requests are not included in this count. This count is exposed as
baseten_concurrent_requests in the metrics dashboard and metrics export.The right value depends on how your model uses hardware. Image generation models that consume all GPU memory per request can only process one at a time, so a concurrency target of 1 is correct. LLMs and embedding models batch requests internally and can handle dozens simultaneously, so higher targets (32 or more) reduce cost by packing more work onto each replica.Tradeoff: Higher concurrency = fewer replicas (lower cost) but more per-replica queueing (higher latency). Lower concurrency = more replicas (higher cost) but less queueing (lower latency).
For engine-specific guidance, see Autoscaling engines.
Concurrency target controls requests sent to a replica and triggers autoscaling.
predict_concurrency (Truss config.yaml) controls requests processed inside the container.
Concurrency target should be less than or equal to predict_concurrency.
See the
predict_concurrency field in the Truss configuration reference for details.integer
default:"70"
Headroom before scaling triggers. The autoscaler scales when utilization reaches this percentage of the concurrency target, not when replicas are fully loaded.Range: 1-100%The effective threshold is:With a concurrency target of 10 and utilization of 70%, scaling triggers at 7 concurrent requests (10 × 0.70), leaving 30% headroom for absorbing spikes while new replicas start.Lower values (50-60%) provide more headroom for spikes but cost more. Higher values (80%+) are cost-efficient for steady traffic but absorb spikes less effectively.
Scaling dynamics
Once the autoscaler decides to scale, the settings here control the pace.autoscaling_window determines how much history feeds into each decision, so a longer window averages out short spikes while a shorter one reacts to traffic changes faster. scale_down_delay gates removal in the other direction by holding replicas warm even after load drops, so a brief dip does not trigger a teardown that the next request would have to wait through. max_scale_down_rate caps how much capacity each scale-down step can remove once that delay has passed. Together, these settings tune the tradeoff between responsiveness and stability. The diagram below shows traffic falling to zero, the idle timer filling up, and the replica being reclaimed only once the timer crosses the scale_down_delay threshold.
integer
default:"60"
How far back (in seconds) the autoscaler looks when measuring traffic. Traffic is averaged over this window to make scaling decisions.Range: 10-3600 secondsA 60-second window smooths out momentary spikes by averaging load over the past minute. Shorter windows (30-60s) react quickly to traffic changes, which suits bursty workloads. Longer windows (2-5 min) ignore short-lived fluctuations and prevent the autoscaler from chasing noise.
integer
default:"900"
How long (in seconds) the autoscaler waits after load drops before removing replicas.Range: 0-3600 secondsWhen load drops, the autoscaler starts a countdown. If load stays low for the full delay, it removes replicas in steps, each capped by
max_scale_down_rate, with a fresh delay between steps. If traffic returns before the countdown finishes, the replicas stay active and the countdown resets.This is your primary lever for preventing oscillation. If replicas repeatedly scale up and down, increase this value first.BIS-LLM deployments default to 300 seconds.integer
default:"50"
The maximum percentage of running replicas the autoscaler can remove in one scale-down step.Range: 1-50%Each time a
scale_down_delay elapses, the autoscaler removes at most this percentage of running replicas. The default of 50% produces the halve-and-wait pattern described above. Lower values release capacity more gradually, which keeps more replicas warm when traffic tends to rebound shortly after it drops.BIS-LLM deployments default to 20% because replicas hold KV cache that’s expensive to rebuild.Development deployments
Development deployments are designed for iteration, not production traffic. Replicas are fixed at 0-1 to match thetruss watch workflow, where you’re testing changes on a single instance rather than handling concurrent users. You can still adjust timing and concurrency settings.
To enable full autoscaling with configurable replica settings, promote the deployment to production.
Next steps
Traffic patterns
Identify your traffic pattern and get recommended starting settings.
Cold starts
Understand cold starts and how to minimize their impact.
API reference
Complete autoscaling API documentation.
Engine-specific autoscaling
Recommended settings for BEI and Engine-Builder-LLM with dynamic batching.