How you develop a model
You work with a Truss at increasing levels of control, and you only go as deep as your model requires:- The CLI runs the loop you live in.
truss push --watchcreates a development deployment,truss watchlive-patches your changes in seconds, andtruss push --promoteships to production. See The development loop. config.yamldeclares your runtime: GPU, dependencies, base image, and weights. Most popular open-source LLMs deploy from config alone, served on TensorRT-LLM with an OpenAI-compatible API and no code required. See Configuration and Dependencies.model/model.pyholds custom code. Write a PythonModelclass withloadandpredictwhen configuration can’t express your logic, such as custom preprocessing, postprocessing, or an unsupported architecture. See The Model class.
Pick a starting point
- Config-only: Deploy a model from a single
config.yaml. Start with Build your first model. - Custom Python: Write a
Modelclass with__init__,load, andpredict. Start with The Model class. - Custom Docker: Bring your own container. See Custom Docker servers.
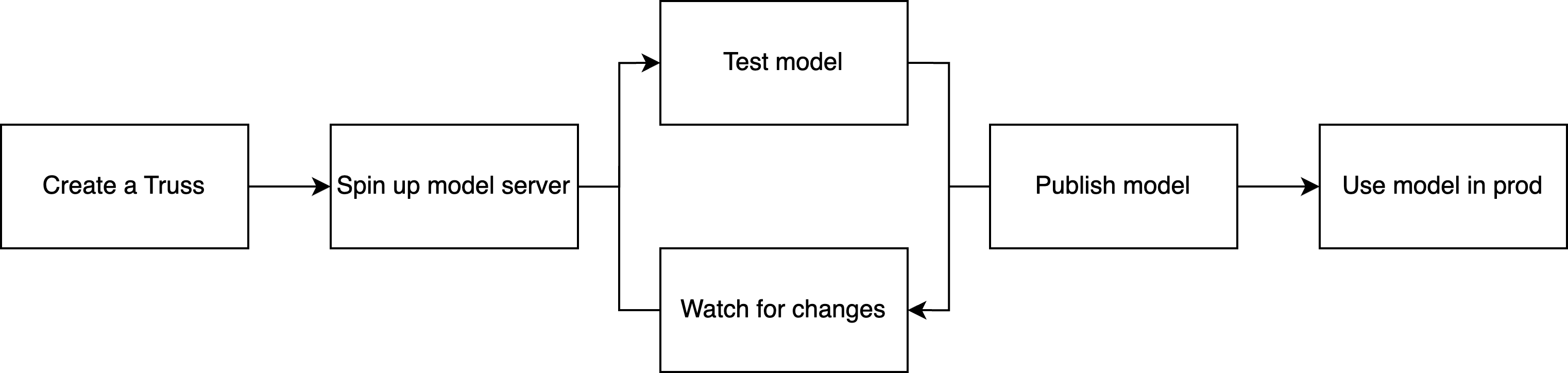
The development cycle
Whichever surface you use, the iteration workflow is the same: push a development deployment, make changes with live reload, and publish when you’re ready for production traffic.- Push to development. Run
truss push --watchto create a development deployment, a single-replica instance with live reload enabled, designed for fast iteration rather than production traffic. - Iterate with live reload. Run
truss watchto start a file watcher that syncs local changes to your development deployment in seconds, without rebuilding the container. Edit, save, and see the result in the deployment logs. - Publish to production. Run
truss pushto create an immutable, production-ready deployment with full autoscaling. Promote it to an environment for a stable endpoint URL that doesn’t change between versions.