truss push, Baseten creates a deployment: a running instance of your model on GPU infrastructure with an API endpoint. This page explains how deployments are managed, versioned, and scaled. For the operations themselves, see Manage deployments.
Deployments
A deployment is a single version of your model running on specific hardware. Everytruss push creates a new deployment. You can have multiple deployments of the same model running simultaneously, which is how you test new versions without affecting production traffic. Deployments can be deactivated to stop serving (and stop incurring cost) or deleted permanently when they’re no longer needed.
For rapid iteration, use truss push --watch to create a development deployment, a mutable instance that live-reloads as you edit your model code. Development deployments can’t be promoted to an environment.
Environments
As your model matures, you’ll want a way to manage releases. Environments provide stable endpoints that persist across deployments. A typical setup has a development environment for testing and a production environment for live traffic. Each environment maintains its own autoscaling settings, metrics, and endpoint URL. When a new deployment is ready, you promote it to an environment, and traffic shifts to the new version without changing the endpoint your application calls.
Resources
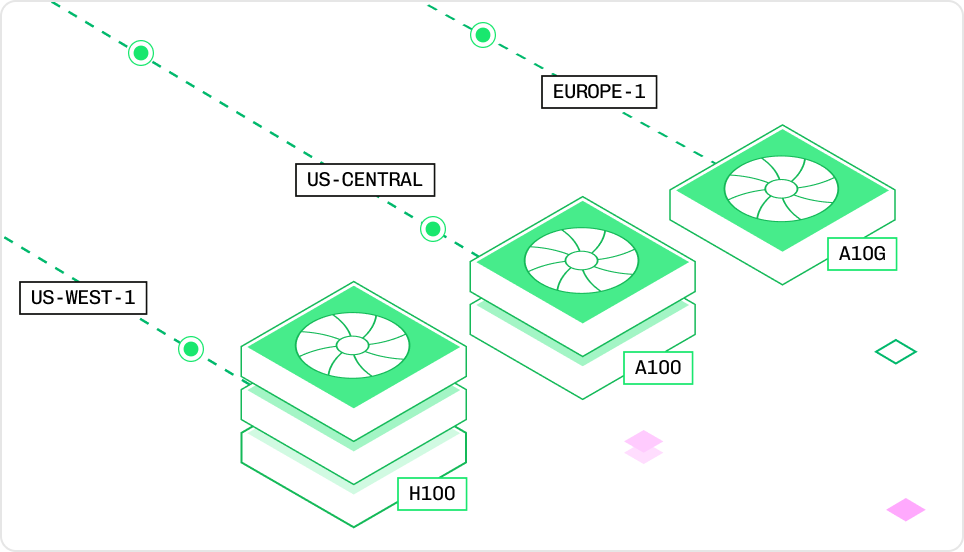
Every deployment runs on a specific instance type that defines its GPU, CPU, and memory allocation. Choosing the right instance balances inference speed against cost. You’ll set the instance type in yourconfig.yaml before deployment, or adjust it later through the Baseten UI. Smaller models run well on an L4 (24 GB VRAM), while large LLMs may need A100s or H100s with tensor parallelism across multiple GPUs.
Autoscaling
You don’t manage replicas manually. Autoscaling adjusts the number of running instances based on incoming traffic. You’ll configure a minimum and maximum replica count, a concurrency target, and a scale-down delay. When traffic drops, replicas scale down (optionally to zero, eliminating all cost). When traffic spikes, new replicas spin up automatically. Cold start optimization and network acceleration keep response times fast even when scaling from zero. For the mechanics of how the autoscaler tracks in-flight requests and adjusts replicas, see How Baseten works. For engine-specific autoscaling settings (BEI and Engine-Builder-LLM), see Autoscaling engines.
For the mechanics of how the autoscaler tracks in-flight requests and adjusts replicas, see How Baseten works. For engine-specific autoscaling settings (BEI and Engine-Builder-LLM), see Autoscaling engines.