View on GitHub
Install the client
- Python
- JavaScript
Install the Performance Client:
Terminal
Get started
- Python
- JavaScript
To initialize the Performance Client in Python, import the class and provide your base URL and API key:
quickstart.py
base_url.
Advanced setup
Configure HTTP version selection and connection pooling for optimal performance.- Python
- JavaScript
To configure HTTP version and connection pooling in Python, use the
http_version parameter and HttpClientWrapper:advanced_setup.py
Core features
The client requests MessagePack (msgpack) responses and zstd compression through its defaultAccept and Accept-Encoding headers, and decodes MessagePack responses transparently. Setting either header yourself overrides the default.
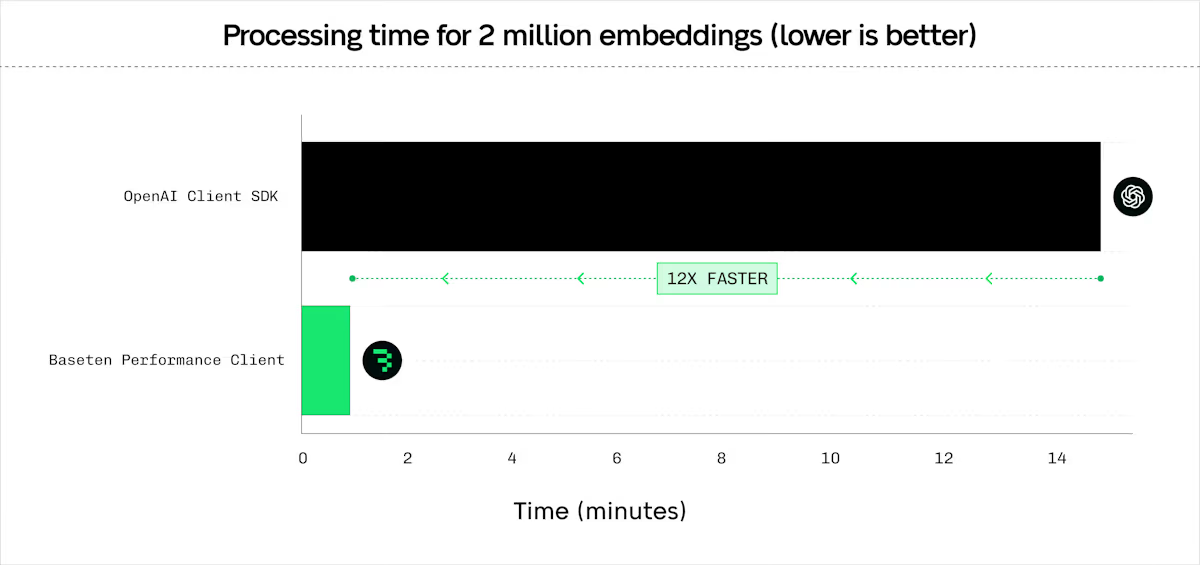
Embeddings
The client provides efficient embedding requests with configurable batching, concurrency, and latency optimizations. Compatible with BEI.- Python
- JavaScript
To generate embeddings with Python, configure a For async usage, call
RequestProcessingPreference and call client.embed():embed.py
await client.async_embed(input=texts, model="my_model", preference=preference).Generic batch POST
Send HTTP requests to any URL with any JSON payload. Compatible with Engine-Builder-LLM and other models. Setstream=False for SSE endpoints.
- Python
- JavaScript
To send batch POST requests with Python, define your payloads and call Supported methods:
client.batch_post():batch_post.py
GET, POST, PUT, PATCH, DELETE, HEAD, OPTIONS.For async usage, call await client.async_batch_post(url_path, payloads, preference, method).Reranking
Rerank documents by relevance to a query. Compatible with BEI, BEI-Bert, and text-embeddings-inference reranking endpoints.- Python
- JavaScript
To rerank documents with Python, provide a query and list of documents to For async usage, call
client.rerank():rerank.py
await client.async_rerank(query, texts, model, return_text, preference).Classification
Classify text inputs into categories. Compatible with BEI and text-embeddings-inference classification endpoints.- Python
- JavaScript
To classify text with Python, provide a list of inputs to For async usage, call
client.classify():classify.py
await client.async_classify(inputs, model, preference).Advanced features
Configure RequestProcessingPreference
TheRequestProcessingPreference class provides unified configuration for all request processing parameters.
- Python
- JavaScript
To configure request processing in Python, create a
RequestProcessingPreference instance:preference.py
Parameter reference
Hedge delay sends duplicate requests after a specified delay to reduce p99 latency. After the delay, the request is cloned and raced against the original. The 429 and 5xx errors are always retried automatically.
Retry configuration
HTTP status-code retries are controlled bymax_retries (maxRetries in JavaScript), which is separate from retry_budget_pct. By default, 408, 409, 429, and 500 through 599 are retried. Set max_retries to 0 to disable these retries.
Use non_retryable_status_codes (nonRetryableStatusCodes in JavaScript) to opt specific status codes out of the default policy. For example, pass {529} in Python or [529] in JavaScript to stop retrying 529 responses.
Backoff starts at initial_backoff_ms (initialBackoffMs in JavaScript), multiplies by 4 after each retry, caps at 45000 milliseconds, and adds up to 99 milliseconds of jitter.
Automatic timeout headers
The Performance Client sends timeout headers with every request so the server can cancel work that exceeds the client’s timeout and return an error before the client gives up. Two headers are derived from thetimeout_s setting in RequestProcessingPreference:
Request-Timeout-Ms: relative timeout in milliseconds, rounded up.Request-Deadline-Ms: absolute deadline as a Unix timestamp in milliseconds.
timeout_s=30.5, the client sends:
Select HTTP version
HTTP/1.1 is recommended for high concurrency workloads.- Python
- JavaScript
To select the HTTP version in Python, use the
http_version parameter:http_version.py
Share connection pools
Share connection pools across multiple client instances to reduce overhead when connecting to multiple endpoints.- Python
- JavaScript
To share a connection pool in Python, create an
HttpClientWrapper and pass it to each client:shared_pool.py
Cancel operations
Cancel long-running operations usingCancellationToken. The token provides immediate cancellation, resource cleanup, Ctrl+C support, token sharing across operations, and status checking with is_cancelled().
- Python
- JavaScript
To cancel operations in Python, create a
CancellationToken and pass it to your preference:cancel.py
Handle errors
The client raises standard exceptions for error conditions:HTTPError: Authentication failures (403), server errors (5xx), endpoint not found (404).Timeout: Request or total operation timeout based ontimeout_sortotal_timeout_s.ValueError: Invalid input parameters (empty input list, invalid batch size, inconsistent embedding dimensions).
- Python
- JavaScript
To handle errors in Python, catch the appropriate exception types:
handle_errors.py
Configure the client
Environment variables
BASETEN_API_KEY: Your Baseten API key. Also checksOPENAI_API_KEYas fallback.PERFORMANCE_CLIENT_LOG_LEVEL: Logging level. OverridesRUST_LOG. Valid values:trace,debug,info,warn,error. Default:warn.PERFORMANCE_CLIENT_REQUEST_ID_PREFIX: Custom prefix for request IDs. Default:perfclient.
Configure logging
To set the logging level, use thePERFORMANCE_CLIENT_LOG_LEVEL environment variable:
Terminal
PERFORMANCE_CLIENT_LOG_LEVEL variable takes precedence over RUST_LOG.
Use with Rust
The Performance Client is also available as a native Rust library. To use the Performance Client in Rust, add the dependencies and create aPerformanceClientCore instance:
main.rs
Cargo.toml:
Cargo.toml
Related
- GitHub: baseten-performance-client: Complete source code and additional examples.
- Performance benchmarks blog: Detailed performance analysis and comparisons.