What does it mean to develop a model?
In Baseten, developing a model means:- Packaging your model code and weights: Wrap your trained model into a structured project that includes your inference logic and dependencies.
- Configuring the model environment: Define everything needed to run your model: Python packages, system dependencies, and secrets.
-
Deploying and iterating quickly:
Push your model to Baseten and iterate with live edits using
truss push --watch.
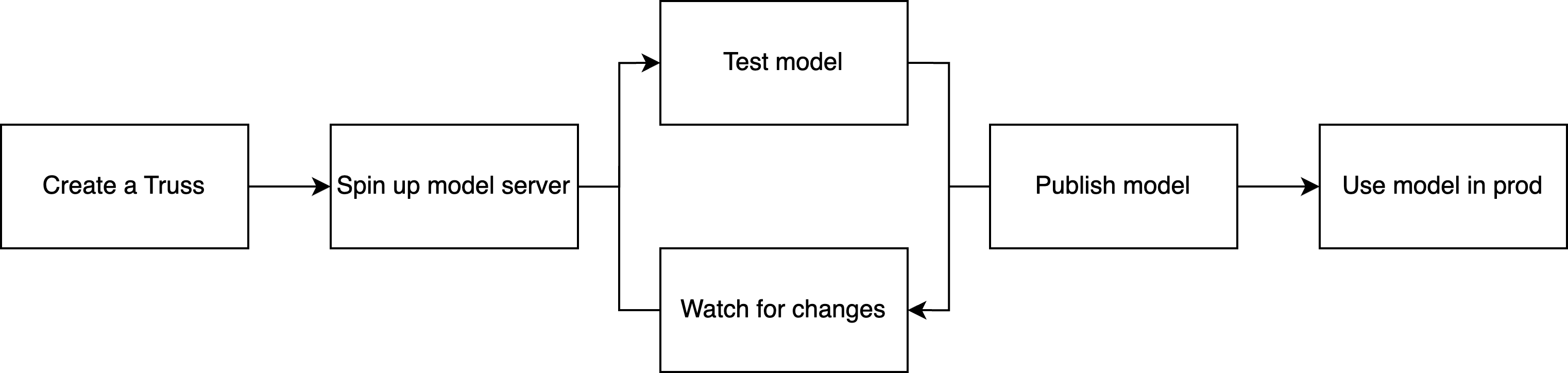
Development flow on Baseten
Here’s what the typical model development loop looks like:-
Initialize a new model project with
truss init. - Add your model logic to a Python class (model.py), specifying how to load and run inference.
- Configure dependencies in a YAML or Python config.
-
Deploy the model with
truss pushfor a published deployment, ortruss push --watchfor a development deployment with live-reloading. -
Iterate and test using
truss watchto sync changes to your dev deployment as you tune the model. -
Promote to production with
truss pushwhen you’re ready to scale.
When you push a model with Truss, it runs in a standardized container on
Baseten without needing Docker installed locally. Truss also gives you a fast
developer loop and a consistent way to configure and serve models.
What is Truss?
Truss is the tool you use to:- Scaffold a new model project
- Serve models locally or in the cloud
- Package your code, config, and model files
- Push to Baseten for deployment
- Model frameworks like PyTorch, transformers, and diffusers
- Inference engines like TensorRT-LLM, SGLang, vLLM
- Serving technologies like Triton
- Any package installable with
piporapt
From model to server: the key components
When you develop a model on Baseten, you define:- A
Modelclass: Defines how your model is loaded (inload) and how inference runs (inpredict). - A configuration file (
config.yamlor Python config): Defines the runtime environment, dependencies, and deployment settings. - Optional extra assets, like model weights, secrets, or external packages.
Development vs. published deployments
By default,truss push creates a published deployment, which is stable, autoscaled, and ready for live traffic.
- Published deployment (
truss push): Stable, autoscaled, and ready for live traffic. Does not support live-reloading. - Development deployment (
truss push --watch): Meant for iteration and testing. Supports live-reloading for quick feedback loops and scales to one replica only.
truss push when you’re satisfied.