Async requests work with any dedicated deployment. You don’t need code changes.
Requests can queue for up to 72 hours and run for up to 1 hour. Async inference is not
compatible with streaming output, and isn’t available on Model APIs.
- Long-running tasks that would otherwise hit request timeouts.
- Batch processing where you don’t need immediate responses.
- Priority queuing to serve VIP customers faster.
Quick start
Set up a webhook endpoint
Create an HTTPS endpoint to receive results. Deploy to any service that can receive POST requests.
Make an async request
Call your model’s You’ll receive a
/async_predict endpoint with your webhook URL:request_id immediately.Receive results
When inference completes, Baseten sends a POST request to your webhook with the model output.
See Webhook payload for the response format.
How async works
Async inference decouples request submission from processing, letting you queue work without waiting for results.Request lifecycle
When you submit an async request:- You call
/async_predictand immediately receive arequest_id. - Your request enters a queue managed by the Async Request Service.
- A background worker picks up your request and calls your model’s predict endpoint.
- Your model runs inference and returns a response.
- Baseten sends the response to your webhook URL using POST.
max_time_in_queue_seconds parameter controls how long a request waits
before expiring. It defaults to 10 minutes but can extend to 72 hours.
Autoscaling behavior
The async queue is decoupled from model scaling. Requests queue successfully even when your model has zero replicas. When your model is scaled to zero:- Your request enters the queue while the model has no running replicas.
- The queue processor attempts to call your model, triggering the autoscaler.
- Your request waits while the model cold-starts.
- Once the model is ready, inference runs and completes.
- Baseten delivers the result to your webhook.
max_time_in_queue_seconds, the
request expires with status EXPIRED. Set this parameter to account for your
model’s startup time. For models with long cold starts, consider keeping minimum
replicas running using
autoscaling settings.
Async priority
Async requests are subject to two levels of priority: how they compete with sync requests for model capacity, and how they’re ordered relative to other async requests in the queue.Sync vs async concurrency
Sync and async requests share your model’s concurrency pool, controlled bypredict_concurrency in your model configuration:
config.yaml
predict_concurrency setting defines how many requests your model can
process simultaneously per replica. When both sync and async requests are in
flight, sync requests take priority. The queue processor monitors your model’s
capacity and backs off when it receives 429 responses, ensuring sync traffic
isn’t starved.
For example, if your model has predict_concurrency=10 and 8 sync requests are
running, only 2 slots remain for async requests. The remaining async requests
stay queued until capacity frees up.
Async queue priority
Within the async queue itself, you can control processing order using thepriority parameter. This is useful for serving specific requests faster or
ensuring critical batch jobs run before lower-priority work. Set the priority field when you submit the request:
async_predict.py
priority parameter accepts values 0, 1, or 2. Lower values indicate higher
priority: a request with priority: 0 is processed before requests with
priority: 1 or priority: 2. If you don’t specify a priority, requests
default to priority 0.
Because unspecified requests default to priority 0, use the priority parameter
mainly to demote less urgent work: set background or batch jobs to priority: 1
or priority: 2 so they yield to default-priority traffic. Marking every request
with the same priority has no effect on ordering.
Watch the queue
Two things decide how quickly an async request clears: itspriority against the
other requests in the queue, and how it competes with sync traffic for replica
capacity. The simulation below shows both. Requests pile up in the async queue, a
load balancer pulls the front of the queue and sends each request to a free replica,
and the replica runs it and frees up for the next.
Requests arrive at the back of the queue and cut ahead of every lower-priority
request, so a priority 0 jumps to the front. The load balancer clears the queue as
fast as it can, always dispatching the front request, so higher-priority work reaches
a replica first. The figure shows each replica handling one request at a time. Switch
to Sync contention to add sync traffic: sync and async share replica capacity, and
sync takes precedence. Sync requests go straight to the replicas, so when sync surges
the load balancer cannot place async work and backs off when it hits a 429. As the
surge recedes, the load balancer drains the backlog across the freed replicas.
Webhooks
Baseten delivers async results to your webhook endpoint when inference completes.Request format
When inference completes, Baseten sends a POST request to your webhook with these headers and body:HTTP request
X-BASETEN-REQUEST-ID header contains the request ID for correlating webhooks with your original requests.
The X-BASETEN-SIGNATURE header is only included if a webhook secret is configured.
Webhook endpoints must use HTTPS (except
localhost for development). Baseten
supports HTTP/2 and HTTP/1.1 connections.Webhook payload
request_id matching your original /async_predict
response, along with model_id and deployment_id identifying which deployment
ran the request. The data field contains your model output, or null if an
error occurred. The errors array is empty on success, or contains error
objects on failure. For what each status code means and how to respond, see Inference errors.
Webhook delivery
Baseten delivers webhooks on a best-effort basis with automatic retries:| Setting | Value |
|---|---|
| Total attempts | 2 (1 initial + 1 retry). |
| Backoff | About 2 seconds before the retry. |
| Timeout | 10 seconds per attempt. |
| Retryable codes | 500, 502, 503, 504. |
- Save outputs in your model. Use the
postprocess()function to write to cloud storage:
model/model.py
postprocess method runs after inference completes. Use
self.context.get('request_id') to access the async request ID for correlating
outputs with requests.
- Use a reliable endpoint. Deploy your webhook to a highly available service like a cloud function or message queue.
Secure webhooks
Create a webhook secret in the Secrets tab to verify requests are from Baseten. When configured, Baseten includes anX-BASETEN-SIGNATURE header:
HTTP header
verify_signature.py
v1= and uses
compare_digest for timing-safe comparison to prevent timing attacks.
Rotate secrets periodically. During rotation, both old and new secrets remain
valid for 24 hours.
Manage requests
You can check the status of async requests or cancel them while they’re queued.Check request status
To check the status of an async request, call the status endpoint with your request ID:request_id only; there’s no environment segment in the path. A request_id is globally unique, so you don’t need to know which environment or deployment originally accepted the request to look it up.
| Status | Description |
|---|---|
QUEUED | Waiting in queue. |
IN_PROGRESS | Currently processing. |
SUCCEEDED | Completed successfully. |
FAILED | Failed after retries. |
EXPIRED | Exceeded max_time_in_queue_seconds. |
CANCELED | Canceled by user. |
WEBHOOK_FAILED | Inference succeeded but webhook delivery failed. |
Cancel a request
OnlyQUEUED requests can be canceled. Once a request enters IN_PROGRESS, the cancel endpoint can’t stop it: the request runs to completion (or fails). If you need to bound how long a request can wait before running, set max_time_in_queue_seconds on the request so stale requests transition to EXPIRED instead of executing.
To cancel a queued request, call the cancel endpoint with your request ID:
cancel_request.py
Error codes
When inference fails, the webhook payload returns anerrors array:
Webhook payload
| Code | HTTP | Description | Retried |
|---|---|---|---|
MODEL_NOT_READY | 400 | Model is loading or starting. | Yes |
MODEL_DOES_NOT_EXIST | 404 | Model or deployment not found. | No |
MODEL_INVALID_INPUT | 422 | Invalid input format. | No |
MODEL_PREDICT_ERROR | 500 | Exception in model.predict(). | Yes |
MODEL_UNAVAILABLE | 502/503 | Model crashed or scaling. | Yes |
MODEL_PREDICT_TIMEOUT | 504 | Inference exceeded timeout. | Yes |
INTERNAL_SERVER_ERROR | N/A | Something went wrong on Baseten. | Yes |
Inference retries
When inference fails with a retryable error, Baseten automatically retries the request using exponential backoff. Configure this behavior withinference_retry_config:
async_predict.py
| Parameter | Range | Default | Description |
|---|---|---|---|
max_attempts | 1-10 | 3 | Total inference attempts including the original. |
initial_delay_ms | 0-10,000 | 1000 | Delay before the first retry (ms). |
max_delay_ms | 0-60,000 | 5000 | Maximum delay between retries (ms). |
max_delay_ms).
Only requests that fail with retryable error codes (500, 502, 503, 504) are
retried. Non-retryable errors like invalid input (422) or model not found (404)
fail immediately.
Inference retries are distinct from webhook delivery retries.
Inference retries happen when calling your model fails. Webhook retries happen
when delivering results to your endpoint fails.
Rate limits
There are rate limits for the async predict endpoint and the status polling endpoint. If you exceed these limits, you’ll receive a 429 status code.| Endpoint | Limit |
|---|---|
Predict endpoint requests (/async_predict) | 12,000 requests/minute (org-level). |
| Status polling | 100 requests/second. |
| Cancel request | 100 requests/second. |
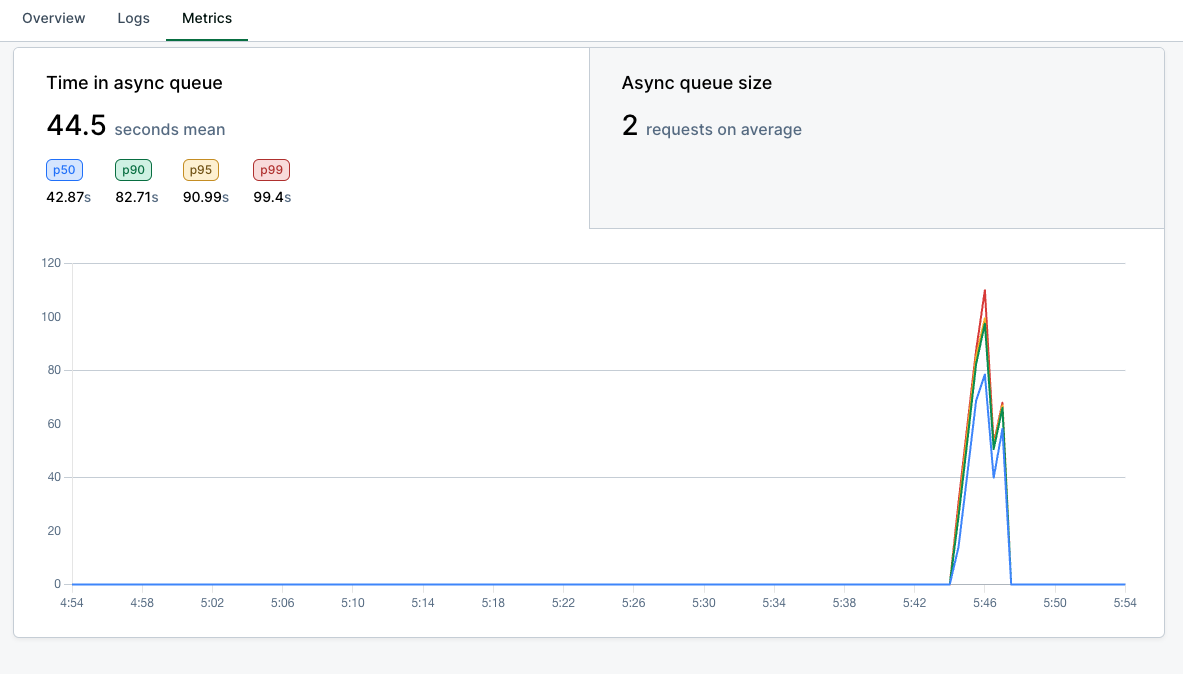
Observability
Async metrics are available on the Metrics tab of your model dashboard:- Inference latency/volume: includes async requests.
- Time in async queue: time spent in
QUEUEDstate. - Async queue size: number of queued requests.
Related
Webhook secrets
Configure webhook secrets in your Baseten settings to secure webhook delivery.