- Lowest-latency inference across any embedding solution (vLLM, SGlang, Infinity, TEI, Ollama)1
- Highest-throughput inference across any embedding solution (vLLM, SGlang, Infinity, TEI, Ollama) - thanks to XQA kernels, FP8 and dynamic batching.2
- High parallelism: up to 1400 client embeddings per second
- Cached model weights for fast vertical scaling and high availability - no Hugging Face hub dependency at runtime
- Ahead-of-time compilation, memory allocation and fp8 post-training quantization
Get started with embedding models:
Embedding models are LLMs without a lm_head for language generation. Typical architectures that are supported for embeddings areLlamaModel, BertModel, RobertaModel or Gemma2Model, and contain the safetensors, config, tokenizer and sentence-transformer config files.
A good example is the repo BAAI/bge-multilingual-gemma2.
To deploy a model for embeddings, set the following config in your local directory.
config.yaml
config.yaml in your local directory, you can deploy the model to Baseten.
Example deployment of classification, reranking, and classification models
Besides embedding models, BEI deploys high-throughput rerank and classification models. You can identify suitable architectures by theirForSequenceClassification suffix in the Hugging Face repo.
The use-case for these models is either Reward Modeling, Reranking documents in RAG or tasks like content moderation.
Benchmarks and performance optimizations
Embedding models on BEI are fast, and offer currently the fastest implementation for embeddings across all open-source and closed-source providers. The team behind the implementation is the authors of infinity. We recommend using fp8 quantization for Llama, Mistral, and Qwen2 models on L4 or newer (L4, H100, H200, and B200). Quality difference between fp8 and bfloat16 is often negligible: embedding models often retain >99% cosine similarity between both precisions, and reranking models retain the ranking order despite a difference in the retained output. For more details, check out the technical launch post.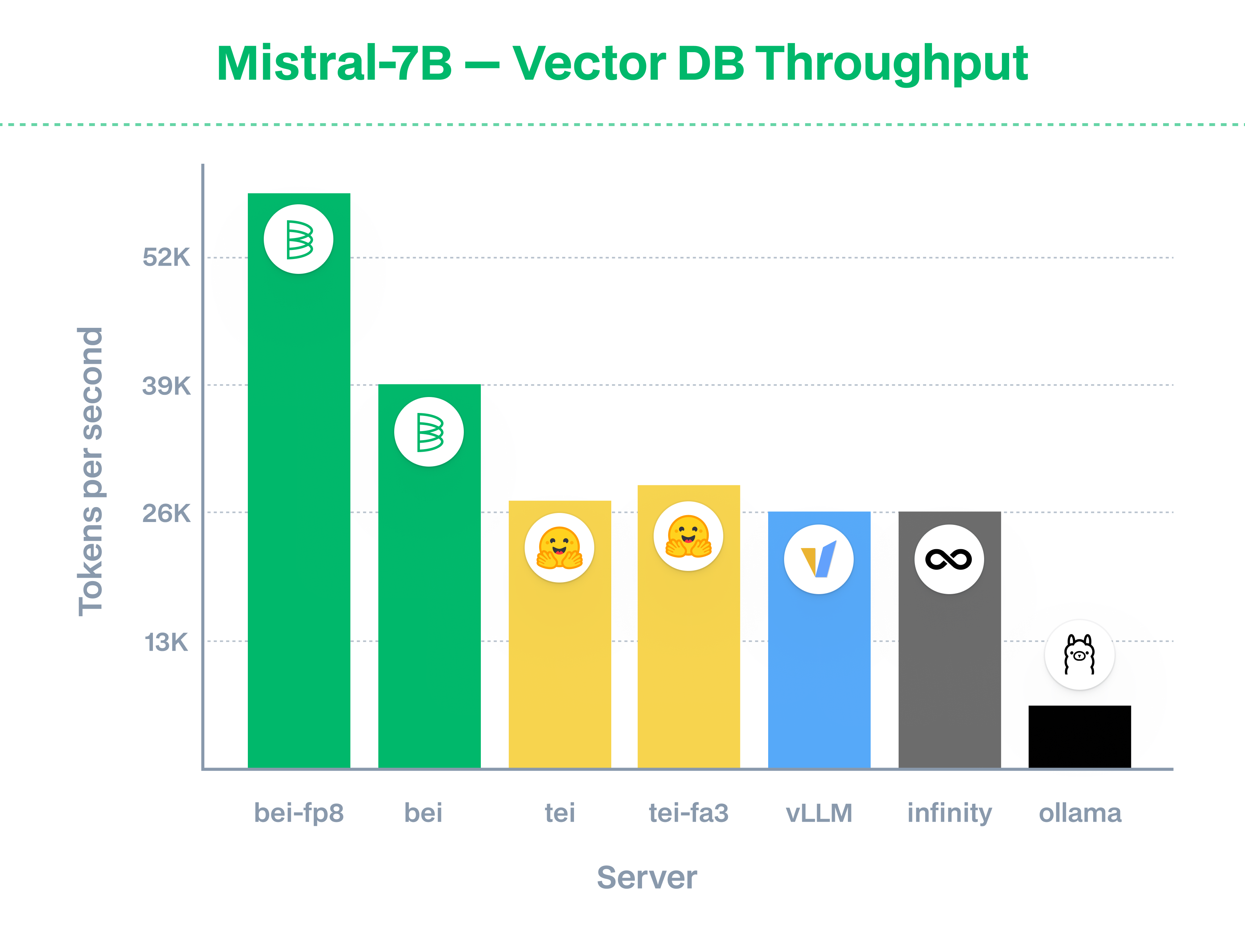
Deploy custom or fine-tuned models on BEI
We support the deployment of the below models, as well as all finetuned variants of these models (same architecture & customized weights). The following repositories are supported - this list is not exhaustive.
1 measured on H100-HBM3 (bert-large-335M, for BAAI/bge-en-icl: 9ms)
2 measured on H100-HBM3 (leading model architecture on MTEB, MistralModel-7B)