> ## Documentation Index
> Fetch the complete documentation index at: https://docs.baseten.co/llms.txt
> Use this file to discover all available pages before exploring further.
# Serve embeddings with BEI
> Deploy embedding, reranking, and classification models on Baseten Embeddings Inference.
Baseten Embeddings Inference is Baseten's solution for production grade inference on embedding, classification and reranking models using TensorRT-LLM.
With Baseten Embeddings Inference you get the following benefits:
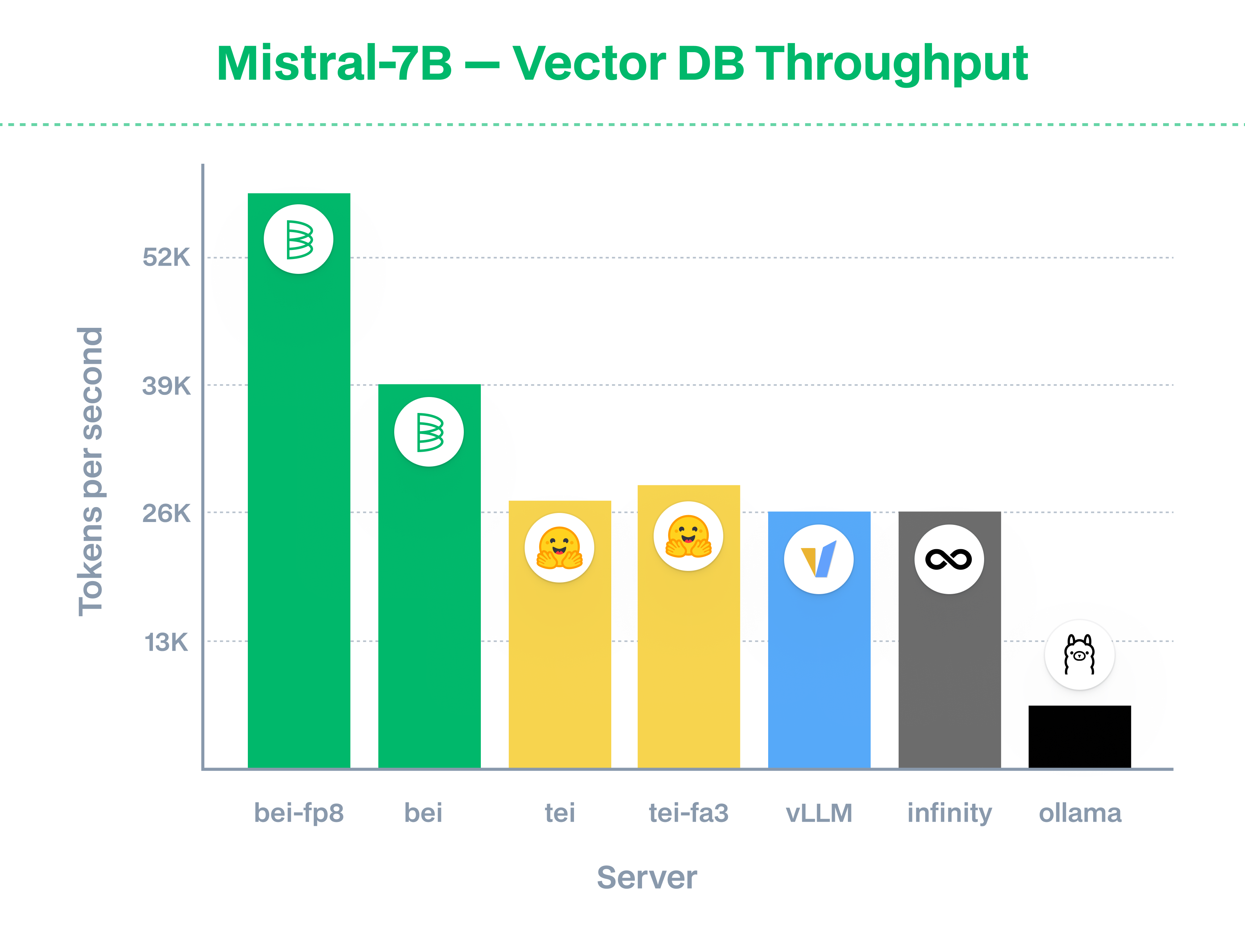
* Lowest-latency inference across any embedding solution (vLLM, SGlang, Infinity, TEI, Ollama)1
* Highest-throughput inference across any embedding solution (vLLM, SGlang, Infinity, TEI, Ollama) - thanks to XQA kernels, FP8 and dynamic batching.2
* High parallelism: up to 1400 client embeddings per second
* Cached model weights for fast vertical scaling and high availability - no Hugging Face hub dependency at runtime
* Ahead-of-time compilation, memory allocation and fp8 post-training quantization
### Get started with embedding models:
Embedding models are LLMs without a lm\_head for language generation.
Typical architectures that are supported for embeddings are `LlamaModel`, `BertModel`, `RobertaModel` or `Gemma2Model`, and contain the safetensors, config, tokenizer and sentence-transformer config files.
A good example is the repo [BAAI/bge-multilingual-gemma2](https://huggingface.co/BAAI/bge-multilingual-gemma2).
To deploy a model for embeddings, set the following config in your local directory.
```yaml config.yaml theme={"system"}
model_name: BEI-Linq-Embed-Mistral
resources:
accelerator: H100_40GB
use_gpu: true
trt_llm:
build:
base_model: encoder
checkpoint_repository:
# for a different model, change the repo to e.g. to "Salesforce/SFR-Embedding-Mistral"
# "BAAI/bge-en-icl" or "BAAI/bge-m3"
repo: "Linq-AI-Research/Linq-Embed-Mistral"
revision: main
source: HF
# only Llama, Mistral and Qwen Models support quantization.
# others, use: "quantization_type: no_quant"
quantization_type: fp8
```
With `config.yaml` in your local directory, you can deploy the model to Baseten.
```bash theme={"system"}
truss push --promote
```
Deployed embedding models are OpenAI compatible without any additional settings.
You may use the client code below to consume the model.
```python theme={"system"}
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ['BASETEN_API_KEY'],
# add the deployment URL
base_url="https://model-xxxxxx.api.baseten.co/environments/production/sync/v1"
)
embedding = client.embeddings.create(
input=["Baseten Embeddings are fast.", "Embed this sentence!"],
model="not-required"
)
```
### Example deployment of classification, reranking, and classification models
Besides embedding models, BEI deploys high-throughput rerank and classification models.
You can identify suitable architectures by their `ForSequenceClassification` suffix in the Hugging Face repo.
The use-case for these models is either Reward Modeling, Reranking documents in RAG or tasks like content moderation.
```yaml theme={"system"}
model_name: BEI-mixedbread-rerank-large-v2-fp8
resources:
accelerator: H100_40GB
cpu: '1'
memory: 10Gi
use_gpu: true
trt_llm:
build:
base_model: encoder
checkpoint_repository:
repo: michaelfeil/mxbai-rerank-large-v2-seq
revision: main
source: HF
# only Llama, Mistral and Qwen Models support quantization
quantization_type: fp8
```
As OpenAI does not offer reranking or classification, we are sending a simple request to the endpoint.
Depending on the model, you might want to apply a specific prompt template first.
```python theme={"system"}
import requests
import os
headers = {
f"Authorization": f"Bearer {os.environ['BASETEN_API_KEY']}"
}
# model specific prompt for mixedbread's reranker v2.
prompt = (
"<|endoftext|><|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.\n<|im_end|>\n<|im_start|>user\n"
"query: {query} \ndocument: {doc} \nYou are a search relevance expert who evaluates how well documents match search queries. For each query-document pair, carefully analyze the semantic relationship between them, then provide your binary relevance judgment (0 for not relevant, 1 for relevant).\nRelevance:<|im_end|>\n<|im_start|>assistant\n"
).format(query="What is Baseten?",doc="Baseten is a fast inference provider.")
requests.post(
headers=headers,
url="https://model-xxxxxx.api.baseten.co/environments/production/sync/predict",
json={
"inputs": prompt,
"raw_scores": True,
}
)
```
### Benchmarks and performance optimizations
Embedding models on BEI are fast, and offer currently the fastest implementation for embeddings across all open-source and closed-source providers.
The team behind the implementation is the authors of [infinity](https://github.com/michaelfeil/infinity).
We recommend using fp8 quantization for Llama, Mistral, and Qwen2 models on L4 or newer (L4, H100, H200, and B200).
Quality difference between fp8 and bfloat16 is often negligible: embedding models often retain >99% cosine similarity between both precisions,
and reranking models retain the ranking order despite a difference in the retained output.
For more details, check out the [technical launch post](https://www.baseten.co/blog/how-we-built-high-throughput-embedding-inference-with-tensorrt-llm/).
 The team at Baseten has additional options for sharing cached model weights across replicas - for very fast horizontal scaling.
Please contact us to enable this option.
### Deploy custom or fine-tuned models on BEI
We support the deployment of the below models, as well as all finetuned variants of these models (same architecture & customized weights).
The following repositories are supported - this list is not exhaustive.
| Model Repository | Architecture | Function |
| ------------------------------------------------------------------------------------------------------------- | ----------------------------------- | ------------------- |
| [`Salesforce/SFR-Embedding-Mistral`](https://huggingface.co/Salesforce/SFR-Embedding-Mistral) | MistralModel | embedding |
| [`BAAI/bge-m3`](https://huggingface.co/BAAI/bge-m3) | BertModel | embedding |
| [`BAAI/bge-multilingual-gemma2`](https://huggingface.co/BAAI/bge-multilingual-gemma2) | Gemma2Model | embedding |
| [`mixedbread-ai/mxbai-embed-large-v1`](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) | BertModel | embedding |
| [`BAAI/bge-large-en-v1.5`](https://huggingface.co/BAAI/bge-large-en-v1.5) | BertModel | embedding |
| [`allenai/Llama-3.1-Tulu-3-8B-RM`](https://huggingface.co/allenai/Llama-3.1-Tulu-3-8B-RM) | LlamaForSequenceClassification | classifier |
| [`ncbi/MedCPT-Cross-Encoder`](https://huggingface.co/ncbi/MedCPT-Cross-Encoder) | BertForSequenceClassification | reranker/classifier |
| [`SamLowe/roberta-base-go_emotions`](https://huggingface.co/SamLowe/roberta-base-go_emotions) | XLMRobertaForSequenceClassification | classifier |
| [`mixedbread/mxbai-rerank-large-v2-seq`](https://huggingface.co/michaelfeil/mxbai-rerank-large-v2-seq) | Qwen2ForSequenceClassification | reranker/classifier |
| [`BAAI/bge-en-icl`](https://huggingface.co/BAAI/bge-en-icl) | LlamaModel | embedding |
| [`BAAI/bge-reranker-v2-m3`](https://huggingface.co/BAAI/bge-reranker-v2-m3) | BertForSequenceClassification | reranker/classifier |
| [`Skywork/Skywork-Reward-Llama-3.1-8B-v0.2`](https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B-v0.2) | LlamaForSequenceClassification | classifier |
| [`Snowflake/snowflake-arctic-embed-l`](https://huggingface.co/Snowflake/snowflake-arctic-embed-l) | BertModel | embedding |
| [`nomic-ai/nomic-embed-code`](https://huggingface.co/nomic-ai/nomic-embed-code) | Qwen2Model | embedding |
1 measured on H100-HBM3 (bert-large-335M, for BAAI/bge-en-icl: 9ms)
2 measured on H100-HBM3 (leading model architecture on MTEB, MistralModel-7B)
The team at Baseten has additional options for sharing cached model weights across replicas - for very fast horizontal scaling.
Please contact us to enable this option.
### Deploy custom or fine-tuned models on BEI
We support the deployment of the below models, as well as all finetuned variants of these models (same architecture & customized weights).
The following repositories are supported - this list is not exhaustive.
| Model Repository | Architecture | Function |
| ------------------------------------------------------------------------------------------------------------- | ----------------------------------- | ------------------- |
| [`Salesforce/SFR-Embedding-Mistral`](https://huggingface.co/Salesforce/SFR-Embedding-Mistral) | MistralModel | embedding |
| [`BAAI/bge-m3`](https://huggingface.co/BAAI/bge-m3) | BertModel | embedding |
| [`BAAI/bge-multilingual-gemma2`](https://huggingface.co/BAAI/bge-multilingual-gemma2) | Gemma2Model | embedding |
| [`mixedbread-ai/mxbai-embed-large-v1`](https://huggingface.co/mixedbread-ai/mxbai-embed-large-v1) | BertModel | embedding |
| [`BAAI/bge-large-en-v1.5`](https://huggingface.co/BAAI/bge-large-en-v1.5) | BertModel | embedding |
| [`allenai/Llama-3.1-Tulu-3-8B-RM`](https://huggingface.co/allenai/Llama-3.1-Tulu-3-8B-RM) | LlamaForSequenceClassification | classifier |
| [`ncbi/MedCPT-Cross-Encoder`](https://huggingface.co/ncbi/MedCPT-Cross-Encoder) | BertForSequenceClassification | reranker/classifier |
| [`SamLowe/roberta-base-go_emotions`](https://huggingface.co/SamLowe/roberta-base-go_emotions) | XLMRobertaForSequenceClassification | classifier |
| [`mixedbread/mxbai-rerank-large-v2-seq`](https://huggingface.co/michaelfeil/mxbai-rerank-large-v2-seq) | Qwen2ForSequenceClassification | reranker/classifier |
| [`BAAI/bge-en-icl`](https://huggingface.co/BAAI/bge-en-icl) | LlamaModel | embedding |
| [`BAAI/bge-reranker-v2-m3`](https://huggingface.co/BAAI/bge-reranker-v2-m3) | BertForSequenceClassification | reranker/classifier |
| [`Skywork/Skywork-Reward-Llama-3.1-8B-v0.2`](https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B-v0.2) | LlamaForSequenceClassification | classifier |
| [`Snowflake/snowflake-arctic-embed-l`](https://huggingface.co/Snowflake/snowflake-arctic-embed-l) | BertModel | embedding |
| [`nomic-ai/nomic-embed-code`](https://huggingface.co/nomic-ai/nomic-embed-code) | Qwen2Model | embedding |
1 measured on H100-HBM3 (bert-large-335M, for BAAI/bge-en-icl: 9ms)
2 measured on H100-HBM3 (leading model architecture on MTEB, MistralModel-7B)